MovieTaster-使用Item2Vec做电影推荐
Published:
自从Mikolov在他2013年的论文“Efficient Estimation of Word Representation in Vector Space”[1]提出词向量的概念后,NLP领域仿佛一下子进入了embedding的世界,Sentence2Vec、Doc2Vec、Everything2Vec。词向量基于语言模型的假设——“一个词的含义可以由它的上下文推断得出“,提出了词的Distributed Representation表示方法。相较于传统NLP的高维、稀疏的表示法(One-hot Representation),Word2Vec训练出的词向量是低维、稠密的。Word2Vec利用了词的上下文信息,语义信息更加丰富,目前常见的应用有:
- 使用训练出的词向量作为输入特征,提升现有系统,如应用在情感分析、词性标注、语言翻译等神经网络中的输入层。
- 直接从语言学的角度对词向量进行应用,如使用向量的距离表示词语相似度、query相关性等。
MovieTaster
MovieTaster是我用Item2Vec实现的电影推荐demo,它可以针对输入的一个或多个电影,基于豆瓣用户UGC内容(豆列)产生推荐列表。Github Repo
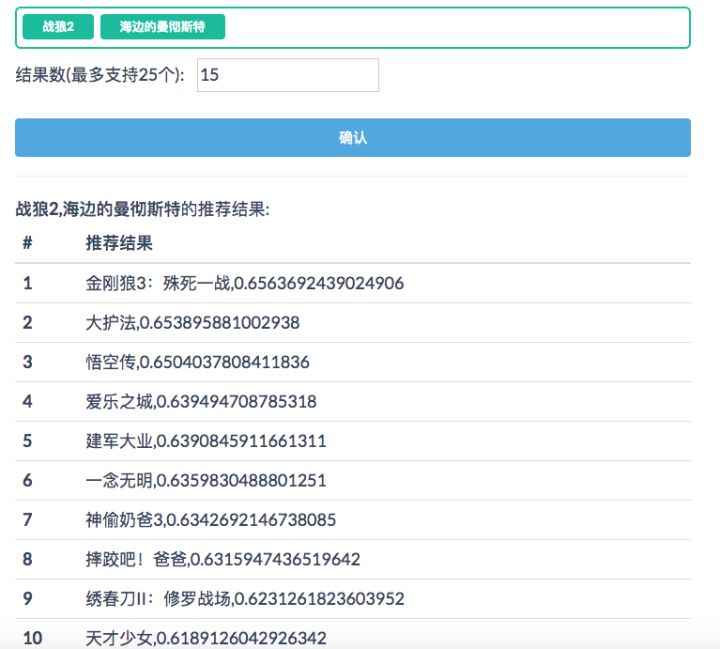
MovieTaster-demo-输入多个电影
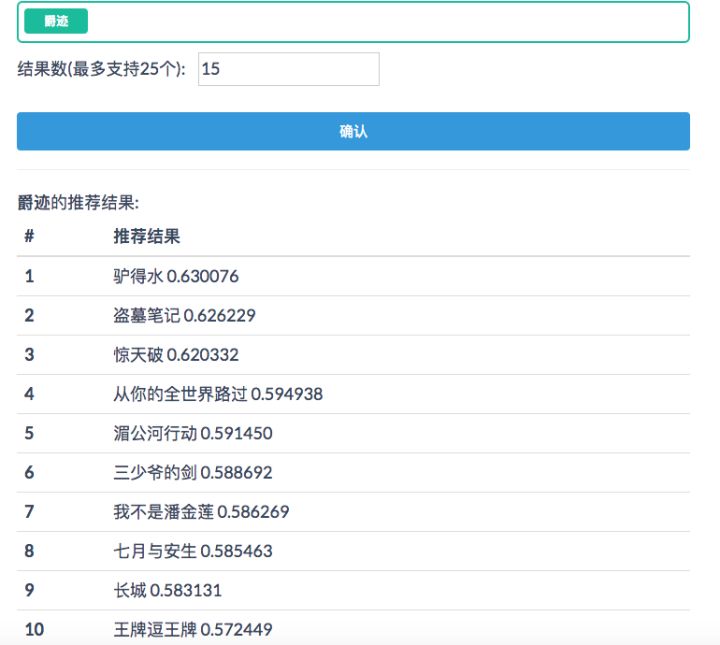
MovieTaster-demo-输入单个电影
Item2Vec
MovieTaster是Item2Vec在电影推荐上的实现,下面简单介绍一下Item2Vec的内容。
Item2Vec是由O Barkan,N Koenigstein在他们2016年的论文“Item2Vec: Neural Item Embedding for Collaborative Filtering“[3]中提出的。论文把Word2vec的Skipgram with Negative Sampling (SGNS)的算法思路迁移到基于物品的协同过滤(item-based CF)上,以物品的共现性作为自然语言中的上下文关系,构建神经网络学习出物品在隐空间的向量表示。论文中还比较了Item2Vec和SVD在微软Xbox音乐推荐服务和Windows 10商店的商品推荐的效果,结果显示Item2Vec效果有所提升。
总的来说,这篇论文的算法创新性不高,但把Word2Vec迁移到item-based CF的脑洞令人耳目一新。在Item2Vec中,一个物品集合被视作自然语言中的一个段落,物品集合的基本元素-物品等价于段落中的单词。因此在论文中,一个音乐物品集合是用户对某歌手歌曲的播放行为,一个商品集合是一个订单中包含的所有商品。
从自然语言序列迁移到物品集合,丢失了空间/时间信息,还无法对用户行为程度建模(喜欢和购买是不同程度的强行为)。好处是可以忽略用户-物品关系,即便获得的订单不包含用户信息,也可以生成物品集合。而论文的结论证明,在一些场景下序列信息的丢失是可忍受的。
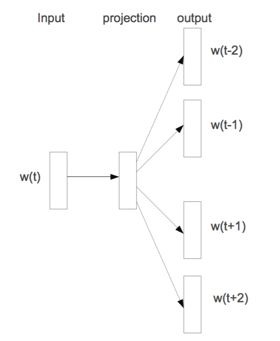
skipgram网络结构
Item2Vec的网络结构与Word2Vec Skipgram的结构基本一致,只是输入的w(t)替换为i(t)。论文中还提到,由于训练数据迁移到物品集合,模型需要进行调整才能保证效果:
(1) 把Word2Vec的上下文窗口(window size)由定长的修改为变长的,长度由当前训练的物品集合长度决定。此方法需要修改网络结构。
(2) 不修改网络结构,而在训练神经网络时对物品集合做shuffle操作,变相地起到忽略序列带来对影响。 论文提出两种方法的实验效果基本一致。
MovieTaster是如何实现的
MovieTaster的训练数据(我爬的)是豆友们的电影豆列共6万个,其中包括10万+部电影。训练item向量使用的工具是fasttext,训练方式是skipgram、50个epoch,并滤去出现次数低于10次的电影。
我还尝试了其它训练参数,推荐结果如下:
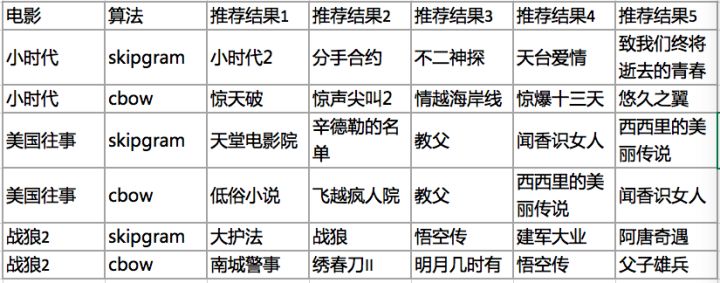
skipgram-vs-cbow
从结果中可以观察出一些有意思的结论。战狼2是最近刚出的电影(此文作于2017/08),包含战狼2的大多是“暑期国产电影合集”,“2017年不得不看的国产电影“这类豆列;美国往事属于经典老片,训练语料足够多,skipgram和cbow的推荐结果各有千秋;小时代在豆瓣中属于不受待见的一类电影,包含小时代的豆列较少,skipgram的推荐结果优于cbow。
大家关于Item2Vec有什么脑洞,欢迎讨论。文章后续会公开部分源码和数据集,并尝试更多不同算法和参数的效果。
参考资料:
[1] Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
[2] word2vec 中的数学原理详解
[3] Barkan O, Koenigstein N. Item2Vec: Neural Item Embedding for Collaborative Filtering[J]. 2016:1-6.