基于统计信息的新词挖掘实践
Published:
在分词、词性标注、命名实体识别等自然语言处理基础任务,反作弊、知识图谱、新闻热点识别等文本挖掘应用中,未登录词是难以绕开的一个问题。从陌生语料中自动化的新词挖掘是解决该类问题的一种有效方法。
新词挖掘可以分为两大类:
- 基于分词系统的新词挖掘
- 无监督、无知识的新词挖掘
BaizeNLP Open Web Demo
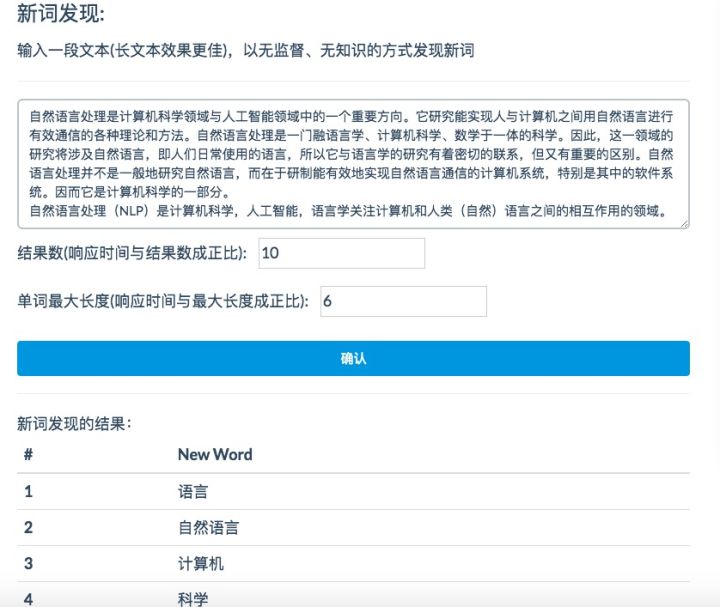
我正在开发的开源NLP工具集BaizeNLP中提供了无监督、无知识的新词挖掘工具,效果如下:(web demo »)
输入文本,自然语言处理的百度百科。
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。
新词挖掘的结果
| # | New Word |
|---|---|
| 1 | 语言 |
| 2 | 自然语言 |
| 3 | 计算机 |
| 4 | 科学 |
| 5 | 领域 |
| 6 | 研究 |
| 7 | 自然语言处理 |
| 8 | 计算机科学 |
| 9 | 是计算机科学 |
| 10 | 重要 |
新词挖掘的原理
BaizeNLP中的新词挖掘算法原理来自Matrix67的互联网时代的社会语言学:基于SNS的文本数据挖掘。
不依赖于任何已有的词库,仅仅根据词的共同特征,将一段大规模语料中可能成词的文本片段全部提取出来,不管它是新词还是旧词。然后,再把所有抽出来的词和已有词库进行比较,不就能找出新词了吗?
Matrix认为,一段文本构成词语由它的内部凝固程度和它的自由运用程度构成。内部凝固程度衡量的是该词语的出现频率和该词语是有意义的搭配的程度,内部凝固程度越高,该文本片段越可能是一个词语;自由运用程度考察的是该词语左右邻字的丰富程度,自由运用程度越高,该文本片段越可能是一个词语。
在自然语言处理的百度百科语料中,部分文本片段的内部凝固程度和自由运用程度如下:
| 文本片段 | 内部凝固程度(bit) | 自由运用程度(bit) | 频率 |
|---|---|---|---|
| 自然 | 7.544 | 0.0 | 9 |
| 然语 | 7.014 | 0.0 | 9 |
| 语言 | 7.014 | 1.509 | 13 |
| 自然语 | 7.014 | 0.0 | 9 |
| 自然语言 | 7.014 | 2.281 | 9 |
| 然语言处 | 7.544 | 0.0 | 4 |
| 自然语言处 | 7.544 | 0.0 | 4 |
| 自然语言处理 | 7.544 | 0.811 | 4 |
| 然语言处理是 | 7.129 | 0.0 | 2 |
工程实现
BaizeNLP的新词挖掘工程实现可以参照源码。简单来说,核心实现包括:
- 由语料的ngram片段建立Trie树和逆序Trie树(
n=词语最大长度+1) - 由Trie树计算片段的出现频次、凝固程度和左邻字符集合熵
- 由逆序Trie树计算片段的右邻字符集合熵
- 计算片段成词的得分
在其他语料上的新词挖掘结果
《西游记》
行者,八戒,师父,三藏,行者道,大圣,一个,唐僧,菩萨,沙僧,和尚,怎么,者道,我们,不知,长老,那里,笑道,妖精,老孙,悟空,甚么,两个,八戒道,国王,徒弟,闻言,那怪,如何,呆子,只见,三藏道,与他,不敢,不曾,宝贝,小妖,原来,大王,道师父,今日,正是,等我,兄弟,出来,叫道,如今,一声,取经,铁棒
《资本论》
资本,生产,价值,劳动,商品,货币,这种,部分,形式,一个,00,工人,这个,利润,我们,作为,价格,因此,产品,剩余,流通,如果,资本家,已经,过程,他们,可以,土地,因为,社会,增加,但是,没有,就是,只是,情况,这样,自己,10,必须,地租,这些,银行
世界,中国,全球,人类,主义,共同,命运,发展,构建,时代,经济,推动,国际,多边,历史,20,治理,合作,多边主义
小说,斯通纳,生活,完美,威廉,力量,意义,是一,是一部,文学,的小说,这本,的一生,追求,或许,献给,艺术,语言,密苏里,勇者